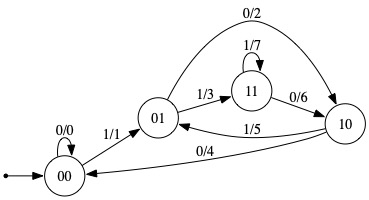
1. Present a Mealy machine having input alphabet {0,1} and output alphabet {0,1,2,3,4,5,6,7} such that each symbol of output indicates the value of the three most recently read bits, interpreted as a binary numeral. (In the case of the first bit of input, the machine should behave as though it was preceded by 00.) It suffices for the machine to "remember" the two most recently read bits.
Here is an example of an input and the output that the machine should produce in response:
| Input: | 1011000111 |
|---|---|
| Output: | 1253640137 |
Solution:
|
|
2. Let L2 be the language over alphabet {a,b} containing precisely those strings that begin with a, end with b, and contain an even number of occurrences of a. Using set comprehension, one could say
(a) Present a (preferably minimal) DFA that accepts L2.
(b) Present a regular expression that denotes L2.
The name of each state in your DFA should be suggestive of some relevant characteristic of the input strings that lead the machine to be in that state.
Solution:
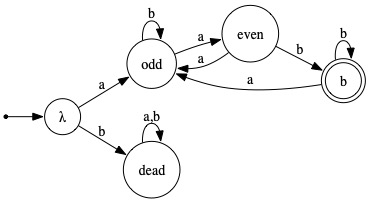
|
The initial a is how to get to state odd from the initial state, λ. The parenthesized part describes those (nonempty) strings by which to get from odd back to odd (without passing through odd). By starring it, we get all strings by which to get from odd back to itself (allowing passing through odd). The ab+ at the end is how to get from odd to final state b for the last time, and then to stay there.
Using the informal description of L2 without considering the DFA of (a), one might come up with this:
The initial a is needed to ensure that all generated strings begin with that symbol. The parenthesized part describes all strings with either zero or two two occurrences of a. By starring it, we get all strings having an even number of occurrences of a. Combining that with the initial a, we have all strings with an odd number of occurrences of a. To get back to an even number, we need the final a, and to ensure that all strings end with at least one b, we tack on the b+.
An alternative is
in which the parenthesized b + ab*a is replaced by b*ab*ab*, the latter of which represents all strings with exactly two occurrences of a.
3. With respect to the DFA shown below, determine the equivalence classes of the state-indistinguishability relation. That is, indicate which states are indistinguishable from each other (and thus would be merged into a single state to form an equivalent minimal DFA). (In order to earn partial credit for an incorrect answer, you must show your work.)
| δ | Symbol | Transition Graph | |||
|---|---|---|---|---|---|
| Initial? | Final? | State | a | b | 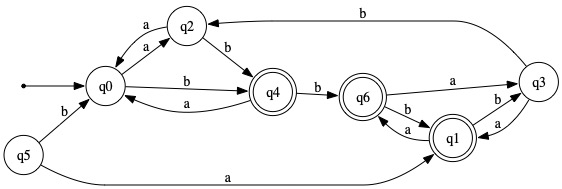 |
| ✓ | q0 | q2 | q4 | ||
| ✓ | q1 | q6 | q3 | ||
| q2 | q0 | q4 | |||
| q3 | q1 | q2 | |||
| ✓ | q4 | q0 | q6 | ||
| q5 | q1 | q0 | |||
| ✓ | q6 | q3 | q1 | ||
The equivalence classes of the state-indistinguishability relation are:
For sake of brevity, in what follows the states will be referred to by their subscript alone, without the "q".
I1 = { {0,2}, {3,5}, {1}, {4,6} }
During Round 2, states 4 and 6 are found to be 2-distinguishable from each other. No other refinements occur, and so we get
I2 = { {0,2}, {3,5}, {1}, {4}, {6} }
Round 3 finds no new distinctions that can be made. Thus, I2 = I3 = ··· I
4.
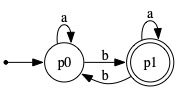 |
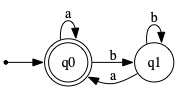 |
| M1 | M2 |
|---|
(a) Give an informal characterization of the members of
L(M1). For a small bonus, use a regular expression
to describe that language.
Solution:
English: The set of all strings over {a,b} having an odd
number of b's.
Set comprehension: { x∈{a,b}* | #b(x) is odd }
Regular expression: Any of these:
a*b(a*ba*ba*)*
a*b(a + ba*b)*
(a + ba*b)*ba*
(b) Repeat the above for L(M2).
Solution:
English: The set of all strings over {a,b} not ending with b
Set comprehension: {λ} ∪ { xa | x∈{a,b}*}
Regular expression: Either of these
(a + b+a)*
λ + (a+b)*a
(c) In the space below, fill in the missing entries in the table that describes the semi-DFA M obtained by applying the cartesian product construction. (A semi-DFA is a DFA except that the final/accepting states are left unspecified.) It is understood that [p0,q0] is the start/initial state, due to p0 (respectively, q0) being the initial state of M1 (resp., M2). (You can draw the transition diagram describing M in the space to the right, but it is not required.)
Solution:
| δ | ||
|---|---|---|
| state | a | b |
| [p0,q0] | [p0,q0] |
[p1,q1] |
| [p0,q1] | [p0,q0] |
[p1,q1] |
| [p1,q0] | [p1,q0] |
[p0,q1] |
| [p1,q1] | [p1,q0] |
[p0,q1] |
(d)
Which state(s) of M should be designated as final/accepting
for the resulting DFA to accept the intersection of
L(M1) and L(M2)?
Solution: [p1,q0] alone.
(e)
Which state(s) of M should be designated as final/accepting
for the resulting DFA to accept the union of
L(M1) and L(M2)?
Solution: [p1,q0], [p1,q1], [p0,q0]
(f)
Suppose that [p0,q1] were the lone state in M to be designated as
final/accepting. What language is accepted by that DFA?
(Try to express it in terms of L(M1), L(M2),
and set operators, as opposed to referring to a's and
b's.)
Solution: (L1 ∪ L2)c
(i.e., the complement of the union of L1 and L2).
Equivalently, that is also
(L1)c ∩ (L2)c
(i.e., the intersection of the complements of L1 and
L2).
5. Imagine that L ⊆ {a,b}* (i.e., L is a language over the alphabet {a,b}) and further imagine that M is an NFA and R is a regular expression such that L(M) = L = L(R). Suppose that we obtain regular expression R' by replacing every occurrence of b in R by b+ (which is shorthand for bb*). As an example, suppose that R were baab*a(a + ba)*. Then R' would be b+aa(b+)*a(a + b+a)*.
Describe the changes to M that would be sufficient to obtain an NFA M' satisfying L(M') = L(R').
Solution: For each state q having a transition labeled b directed to it, add a new state q'. Give q' a transition to itself labeled b and a transition to q labeled λ. For every transition into q labeled b, redirect it to q'.
To express this using diagrams, each occurrence of
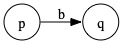 becomes
becomes
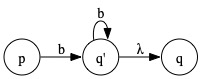
A number of students came up this reasonble, but incorrect, construction:
For every state q that has an incoming transition labeled b, add a transition from q to itself labeled b.
As an exercise, find a counterexample that shows this "solution" to be wrong.
Bonus: Change the problem above to say that every occurrence of b in R is replaced by b*.
Solution: Change the construction just described so that the transitions into q' are labled by λ