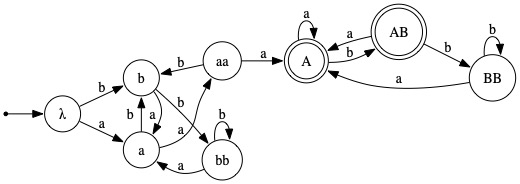
Here is a first solution:
|
|
The state names identify the relevant suffix of whatever portion of the input string has been read so far. Upper case letters are used in the names of states reached after an occurrence of aaa has been read. The machine being in a state named using lower case letters means that no occurrence of aaa has been encountered yet. |
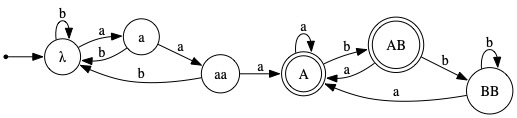
We observe that the states λ, b, and bb are indistinguishable by virtue of the facts that, on input a, all of them go to state a, and on input b, all of them go to "one of their own". Thus, these three states can be merged into a single state, resulting in the minimal DFA below.
|
A number of students, to their credit, presented this minimal DFA. They recognized that, until an occurrence of aaa is encountered, the only distinctions that need to be made are between three categories of strings: those ending with two a's, those ending with only one a, and all others (i.e., the empty string and strings ending with one or more b's). The fact that the empty string is in this third category is why the initial state can be the target of every transition labeled b from any state reached prior to aaa being encountered.
Once an occurrence of aaa has been encountered, all that the machine must "remember" is whether the input read so far ended with a, ab, or bb.
One observes that this language is the union of the language whose members contain exactly two a's (as a regular expression, b*ab*ab*) and the language whose members contain exactly one b (as a regular expression, a*ba*). An NFA for each of these two languages is simple to devise; to obtain an NFA for their union one needs only to introduce a new initial state with λ-transitions to the initial states of the two aforementioned NFAs.
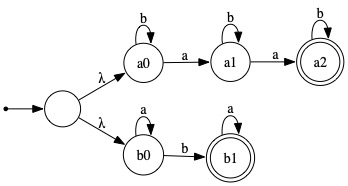
|
For any string containing exactly two a's, there is a
path of transitions from the initial state to state a2
spelling out that string. Hence, this NFA accepts all such strings.
Similarly, for any string containing exactly one b,
there is a path of transitions from the initial state to state
b1 spelling out that string.
Hence, this NFA accepts all such strings.
It follows that this NFA accepts every string in which either
a occurs exactly twice or b occurs exactly once.
Conversely, only strings with exactly two a's can result in a computation ending in state a2, and only strings with exactly one b can result in a computation ending in state a1. Hence, this NFA accepts only such strings. |
3.
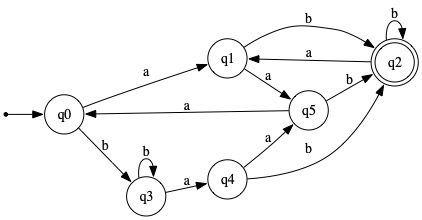
|
Initially, all non-accepting states (which include all but state 2) are assigned to one equivalence class and all accepting states are assigned to the other. That partitioning of the state set corresponds to I0, which relates any pair of states that are indistinguishable by any string of length zero or less. (Clearly, two states are distinguishable by a string of length zero iff one state is accepting and the other is not.)
During "Round 1" of the algorithm, we observe that states 1, 4, and 5 go to an accepting state on input symbol b, which distinguishes them from states 0 and 3, which go to non-accepting states on b. Thus, Round 1 has the effect of splitting equivalence class {0,1,3,4,5} into {0,3} and {1,4,5}, leaving us with the equivalence relation I1 = { {0,3}, {1,4,5}, {2} }.
During "Round 2", we observe that state 5 distinguishes itself from states 1 and 4 on input symbol a. Thus, Round 2 has the effect of splitting state 5 off into its own equivalence class. The resulting equivalence relation is I2 = { {0,3}, {1,4}, {5}, {2} }.
Round 3 finds no distinction between states 0 and 3, nor between states 1 and 4. Hence, I2 = I3 = ... = In = I for all n≥2. Summarizing, we get
| I0: { {0,1,3,4,5}, {2} } |
| I1: { {0,3} {1,4,5}, {2} } |
| I2: { {0,3} {1,4}, {5}, {2} } = I3 = I4 = ... = I |
4.
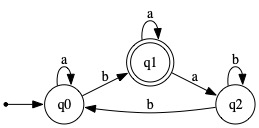
|
Solution #1: The set of strings by which to get to the accepting state, q1, from the initial state, without passing through q1, is L(R), where R is the regular expression a*b.
The set of (non-empty) strings by which to go from q1 back to itself, without passing through itself, is L(S), where S is the regular expression a + ab*ba*b.
It follows that the language accepted by the given NFA is L(R·S*). In gory detail, R·S* is
Solution #2: The set of nonempty strings by which to get from the initial state back to itself, without passing through itself, is L(R), where R is the regular expression (a + ba*ab*b).
The set of strings by which to go from initial state to the accepting state q1, without passing through q1, is L(S), where S is the regular expression a*b.
It follows that the language accepted by the given NFA is L(R*·S). In gory detail, R*·S is
5. The problem was to apply the Subset Construction algorithm to obtain a DFA accepting the same language as the NFA from Problem 4. The result of that is
| δ | Symbol | |||
|---|---|---|---|---|
| Initial? | Final? | State | a | b |
| ∅ | ∅ | ∅ | ||
| ✓ | {q0} | {q0} | {q1} | |
| ✓ | {q1} | {q1,q2} | ∅ | |
| {q2} | ||||
| {q0,q1} | ||||
| {q0,q2} | {q0} | {q0,q1,q2} | ||
| ✓ | {q1,q2} | {q1,q2} | {q0,q2} | |
| ✓ | {q0,q1,q2} | {q0,q1,q2} | {q0,q1,q2} | |
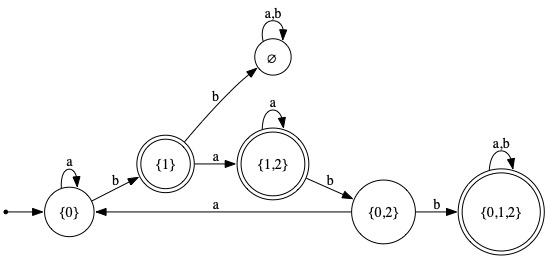
|
||||
It's interesting that, using our intuition, we get a far different regular expression for this DFA than from the equivalent NFA that was given.
The set of strings by which to go from initial state back to itself, without passing through itself, is L(R), where R is the regular expression a + baa*ba.
The set of strings by which to go from initial state to the accepting state {1}, without passing through the initial state is L(S), where S is the regular expression b.
The set of strings by which to go from initial state to the accepting state {1,2}, without passing through the initial state is L(T), where T is the regular expression baa*.
The set of strings by which to go from initial state to the accepting state {0,1,2}, without passing through the initial state is L(U), where U is the regular expression baa*bb(a+b)*.
It follows that the language accepted by the given NFA is L(R*·(S + T + U)). In gory detail, R*·(S + T + U) is
Suppose that M is a minimal DFA with four states and having {a} as its input alphabet. Its lone final/accepting state is the one arrived at from the initial state by following the transition path labeled aa.
From this description, the DFA in question must look like this, with the outgoing transition from state aaa unspecified.

|
That transition could be directed to any of the four states.