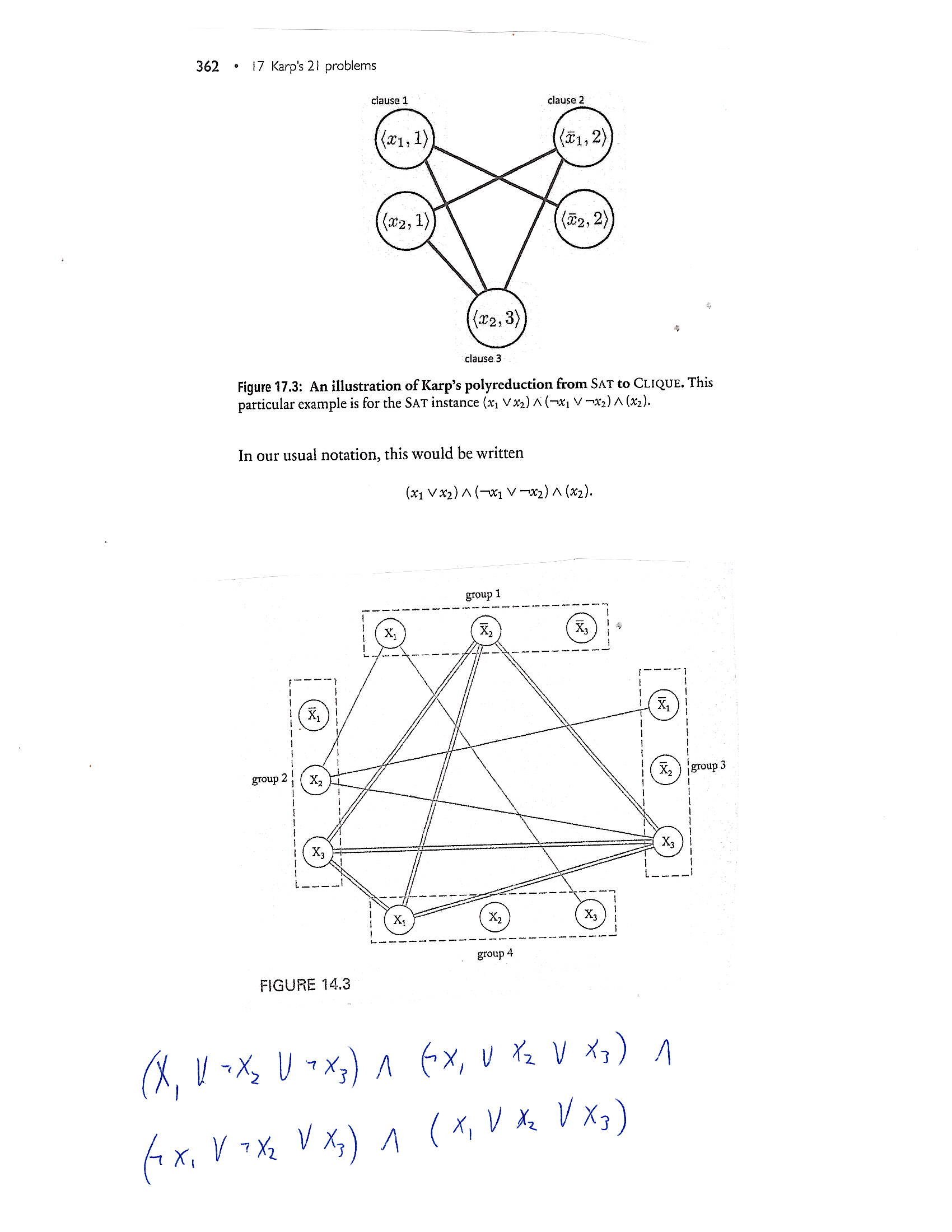
|
Theorem: Let G be a graph having N vertices. Then G has a clique of size k if and only if Gc (the complement of G) has a vertex cover of size N-k.
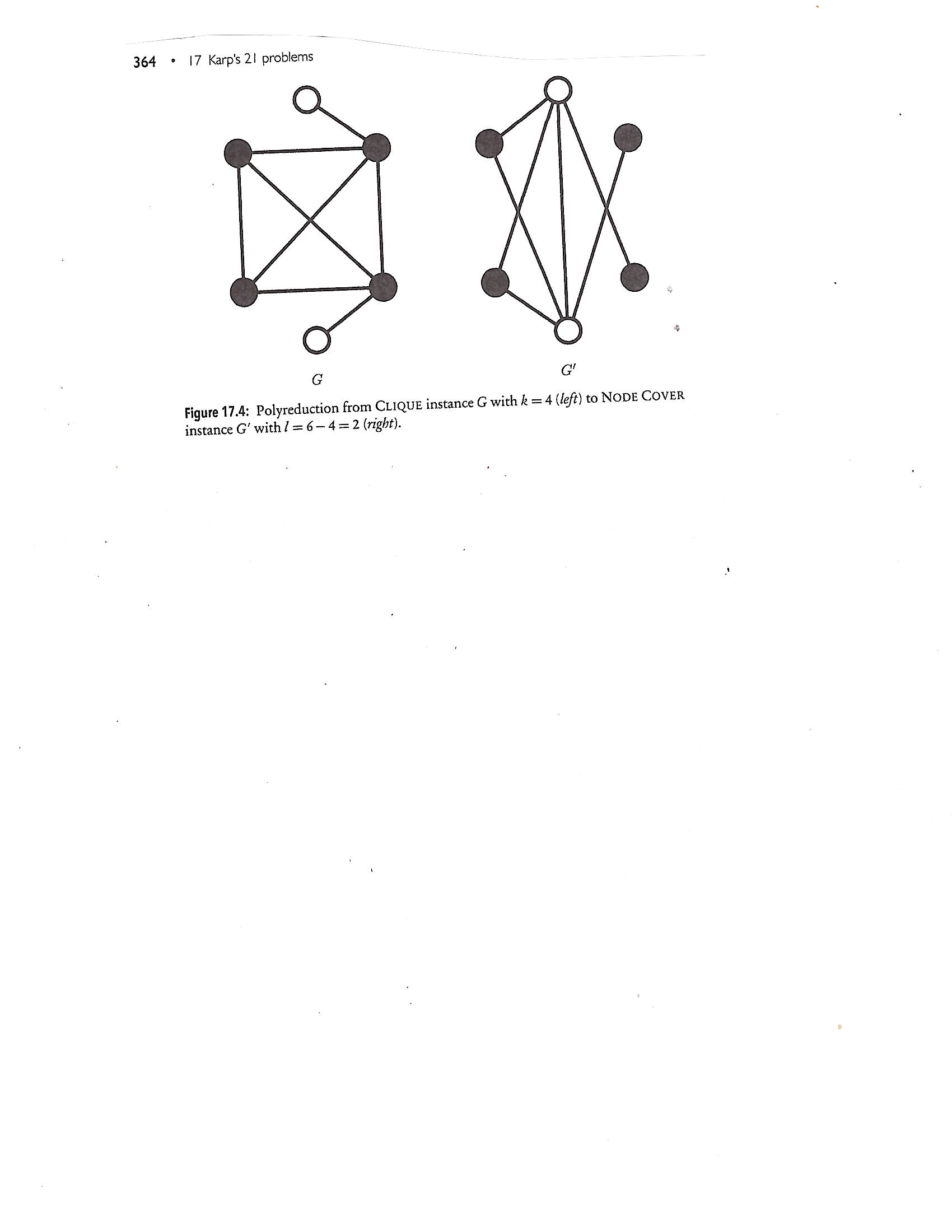
|
In the most recent part of the course, we have been studying the distinction between (decision) problems (equivalently, languages) according to whether or not they are decidable/recursive. Among those languages that are not decidable/recursive, we split them further according to whether or not they are recursively enumerable (aka semi-decidable). This branch of theoretical computer science (TCS) is called computability theory.
Another branch of TCS, complexity theory, attempts to distinguish between decidable/recursive languages/problems according to whether or not they are tractable. An intractable problem would be one for which there is no algorithmic solution that, except when applied to a very small amount of input, would produce a result in a reasonable amount of time.
Although it is a somewhat crude measure, the distinction is based upon whether or not a problem/language has a (deterministic) algorithm that runs in polynomial time, meaning one in the complexity class O(nk), for some k. Problems for which a "best" algorithm runs in exponential time, O(cn) for some constant c, are considered to be intractable.
This is not a perfect distinction, because it would seem to be odd to classify a problem solvable in no better than O(n100) time as being tractable, as n100 is a huge number even when n is small. But such problems do not seem to arise in practice. Indeed, one does not often see exponents of more than, say 4.
On the other hand, it might be unfair to classify a problem that has a O(1.00000001n)-time solution as being intractable, even though that is an exponential running time (and thus, for some threshold n0, 1.00000001n > n100 for all n≥n0. Again, such problems do not seem to arise in practice.
It turns out that there is an interesting class of problems that is widely believed to be intractable, but no one has been able to prove it. These are the NP-Complete problems.
To clarify, such an algorithm that decides language L would, when given string w as input, halt in no more f(|w|) steps (where f(n) is in the class O(nk)) and output either YES or NO. In the case that w ∉ L, it will always output NO. In the case that w ∈ L, there must be at least one computation path that results in it producing YES. (Recall that we have this weird notion that a nondeterministic algorithm will always make a sequence of choices leading to acceptance, if that is possible.)
Of course, every deterministic algorithm is a special case of a nondeterministic algorithm, and thus P ⊆ NP.
There are many interesting problems/languages that are easily shown to be members of NP, but for which we do not know whether they are members of P. Frequently, such problems can be stated in these terms:
Given as input the string x, does the entity/object encoded by x satisfy some particular property of interest?
The language being decided is, of course,
Examples:
E.g., (a ∨ b) ∧ (¬a ∨ ¬b) is satisfiable, but (a ∨ ¬b) ∧ ¬a ∧ (a ∨ b) is not.
Nondeterministic algorithms for such problems are typically expressed as having two phases:
For example, with respect to the problems listed above, a nondeterministic algorithm for CLIQUE can, during its first phase, "guess" a subset of size k of the vertices of G; then, in phase 2, determine whether or not that set of vertices actually forms a clique. If it does, the algorithm answers YES; otherwise it answers NO. If a clique of size k exists in G, there is at least one guess that will lead to YES being produced; hence the algorithm satisfies the requirement of nondeterministically deciding the language.
Note also that both phases can be accomplished in polynomial time (with respect to the length of the encoding <G,k>), so that this algorithm satisfies its running time bounds.
Nondeterministic algorithms of a similar nature exist for the HAMILTONIAN PATH and SATISFIABILITY' problems.
So these three problems, and a number of others, are in the class NP, but are not known to be in P.
For decision problems (in which the question to be answered is whether or not x is a member of some language L), reductions often take this form:
For this to work, it is necessary for there to exist a computable "L to L' conversion function" f : Σ* ⟶ Σ'* (Σ and Σ' being the alphabets of languages L and L', respectively) such that, for all x ∈ Σ*, x ∈ L iff f(x) ∈ L'.
If such a solution to language L exists, we say that L is reducible to L', sometimes written L ≤ L'.
Example: As a simple example, take the languages L1 = { x ∈ {a,b}* | #a(x) = #b(x) } and L2 = { anbn | n≥0 }. Let f() be the function that, applied to a string composed of a's and b's, rearranges them so that it is of the form akbm. Clearly, f is a computable function.
Given a string x ∈ {a,b}*, we can answer the question "Is x ∈ L1?" by answering the question "Is f(x) ∈ L2?". Hence L1 ≤ L2. End of example.
Theorem: Suppose that L ≤ L'. Then
Thus, to prove that a language L' is undecidable, the standard approach is to show that L ≤ L' for some (known-to-be) undecidable L.
Significantly, L ≤p L' implies that if L' is solvable in polynomial time, then so is L. Another significant fact is that ≤p is a transitive relation. That is, if L1 ≤p L2 and L2 ≤p L3, then L1 ≤p L3.
Stephen Cook and (Leonid?) Levin proved that every problem/language in NP is polynomial-time reducible to SAT! Cook did so by showing that, for any fixed TM M that is guaranteed to halt in polynomial time, given a string w, you can (in polynomial time in |w|) construct a CNF formula E that is satisfiable iff M accepts w (i.e., there is an accepting computation in M of w).
Thus, SAT is in the class NP-Complete, which includes any language that is both in NP and is such that every problem in NP is polynomial-time reducible to it.
Among the conclusions that can be drawn are
Over the years, thousands of NP-Complete languages have been identified, many of practical interest. But no one has ever devised a polynomial-time algorithm for any of them. Yet the question as to whether P = NP is still unsolved.
In 1972, Richard Karp identified about 20 NP-Complete problems, which set the ball rolling.
|
|
|
|